🔍 SANA : Explorer les Frontières de la Génération d’Images Haute Résolution avec Transformers Diffusifs Linéaires 🚀
Dans l’univers de l’IA générative, la synthèse d’images haute résolution représente un véritable défi technique et économique. C’est là que SANA entre en jeu, redéfinissant les standards avec une efficacité inégalée.
Mais en quoi ce modèle se distingue-t-il des autres, tels que Flux-12B ou PixArt-Σ, qui dominent actuellement le marché ?

L’un des aspects qui rendent SANA unique est sa capacité à maintenir une qualité d’image exceptionnelle tout en étant 20 fois plus petit et 100 fois plus rapide que ses concurrents. Là où des modèles comme Flux-12B nécessitent une puissance de calcul considérable, SANA fonctionne sur un GPU de 16GB, rendant la génération d’images haute résolution abordable pour un public plus large.
Ce résultat n’est pas dû au hasard, mais repose sur plusieurs innovations clés. L’autoencodeur à compression profonde de SANA est l’un de ses atouts majeurs. Alors que les autoencodeurs traditionnels se contentent d’une compression 8×, SANA pousse cette capacité à 32×, réduisant ainsi de manière significative le nombre de jetons latents à traiter. Cette compression agressive permet de générer des images en 4K, tout en accélérant l’entraînement et l’inférence. Cela signifie que, même pour des tâches complexes, les ressources nécessaires sont considérablement réduites, ouvrant la voie à une adoption plus large, même sur des infrastructures plus modestes.

Autre point fort de SANA : l’utilisation de l’attention linéaire. Contrairement aux approches classiques qui utilisent une attention quadratique, l’attention linéaire optimise le processus en abaissant la complexité de O(N²) à O(N). Cela permet non seulement de traiter plus rapidement des images haute résolution, mais aussi de maintenir une qualité similaire, voire supérieure.
L’absence d’encodage positionnel dans cette architecture est une autre nouveauté, marquant un pas en avant dans l’efficacité des modèles génératifs.
En intégrant Mix-FFN, une couche optimisée qui capte mieux les informations locales des jetons, SANA parvient à produire des images de haute qualité tout en étant plus rapide.

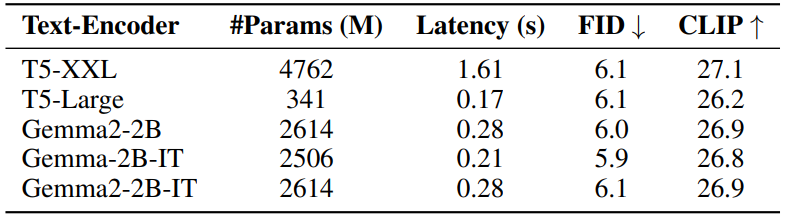
Un autre facteur qui joue en faveur de SANA est son Text Encoder. Plutôt que de s’appuyer sur des modèles comme CLIP ou T5, SANA utilise Gemma, un modèle de langage exclusif aux décodeurs. Ce choix permet d’améliorer la compréhension des instructions textuelles et l’alignement avec les images générées.
L’intégration de techniques avancées comme l’in-context learning permet au modèle de suivre des instructions complexes, tout en garantissant une meilleure cohérence entre le texte et l’image. Les modèles qui utilisent des encoders plus classiques n’arrivent souvent pas à capturer autant de subtilités dans la correspondance texte-image.
Enfin, la stratégie d’inférence proposée par SANA est également un tournant décisif. Grâce à l’implémentation du Flow-DPM-Solver, le nombre d’étapes d’échantillonnage est réduit de 28 à 14, ce qui se traduit par une génération d’image plus rapide, tout en maintenant des performances supérieures. Cela s’avère particulièrement important dans des scénarios de production en temps réel, où la rapidité est cruciale. SANA excelle également dans l’entraînement avec son pipeline de réétiquetage automatique et son approche basée sur le CLIPScore, qui sélectionne les meilleures légendes textuelles pour renforcer l’alignement texte-image.

Avec toutes ces optimisations, SANA-0.6B est aujourd’hui un modèle text-to-image qui surpasse les standards actuels, à la fois en termes de vitesse, de coût et de performance. Il permet de créer des images en très haute définition, tout en étant accessible pour les créateurs et entreprises disposant de ressources matérielles limitées. Cette avancée ouvre des perspectives incroyables pour l’IA générative, où l’efficacité et la qualité ne sont plus des compromis, mais des réalités tangibles.
🌟 SANA en action ? En plus de ses performances impressionnantes, il est important de souligner que le projet SANA sera bientôt disponible pour le public. Bien que les tests en direct ne soient pas encore accessibles, les développeurs prévoient de publier le code source et les modèles dans un avenir proche. Cela offrira aux chercheurs, ingénieurs, créateurs,… la possibilité de découvrir et d’exploiter SANA pour générer des images haute résolution rapidement et à moindre coût.
Pour suivre l’évolution du projet et tester les capacités de SANA dès leur mise en ligne, rendez-vous sur la page officielle : SANA — NVIDIA Labs.
#IA #MachineLearning #GenerativeAI #TextToImage #Innovation #NVIDIA #MIT #Tsinghua #HighResolution #DiffusionModels
🔍 SANA : Explorer les Frontières de la Génération d’Images Haute Résolution avec Transformers… was originally published in ia-web3 on Medium, where people are continuing the conversation by highlighting and responding to this story.