🚀 Google redéfinit les grands modèles de langage : les Relaxed Recursive Transformers révolutionnent l’optimisation de l’IA
Les grands modèles de langage (LLMs) sont devenus incontournables pour les avancées en IA, mais leur coût de déploiement reste un frein majeur. Avec les Relaxed Recursive Transformers, Google introduit une méthode innovante pour rendre ces modèles plus légers tout en conservant des performances comparables. Cette approche repose sur le partage de paramètres entre couches, réduisant considérablement les ressources requises sans compromis significatif sur la précision des résultats.
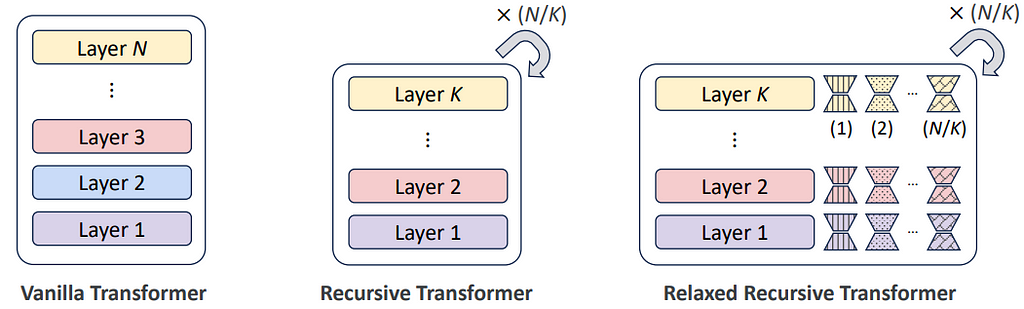
🔄 Recursive Transformers : compacter les modèles par le partage de paramètres
L’idée est radicale mais efficace : au lieu de multiplier les couches indépendantes, les Recursive Transformers utilisent un bloc unique de couches, répliqué en boucle tout au long du modèle. Ce mécanisme de partage de paramètres, ou “layer tying”, permet de maintenir la puissance du modèle tout en réduisant la charge mémoire. En supprimant la redondance dans l’architecture, on diminue le coût de calcul et la mémoire nécessaires pour chaque inférence, ouvrant ainsi la voie à des déploiements de LLMs à moindre coût et plus adaptés aux environnements de production.
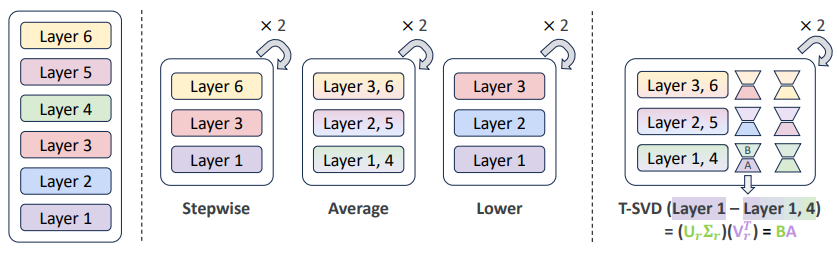
🔧 Relaxed Recursive Transformers : adapter chaque couche avec LoRA pour préserver les nuances contextuelles
Dans certains cas, la répétition de couches pourrait théoriquement limiter la capacité des modèles à s’adapter finement aux variations contextuelles. Pour y remédier, les Relaxed Recursive Transformers intègrent des modules LoRA (Low-Rank Adaptation). Ces modules permettent une adaptation en profondeur, où chaque couche partagée est enrichie par des “deltas de faible rang” qui introduisent des ajustements spécifiques. En variant légèrement les couches à chaque passage, LoRA confère aux modèles une capacité d’adaptation contextuelle qui rivalise avec les architectures complètes, permettant aux Relaxed Recursive Transformers de délivrer des performances proches des versions standards sur des tâches nuancées, tout en maintenant une structure allégée.
📈 Continuous Depth-wise Batching : une avancée pour l’optimisation du débit d’inférence
L’architecture des Recursive Transformers ouvre de nouvelles possibilités en matière d’inférence. Google a ainsi développé le Continuous Depth-wise Batching, une méthode de traitement parallèle qui exploite la répétition des couches.
Cette technique permet de traiter simultanément les différentes itérations d’un même bloc de couches, maximisant ainsi le throughput et réduisant la latence. Associée au early exiting (où seules les étapes nécessaires sont calculées pour chaque token), cette innovation offre une augmentation de 2 à 3 fois du throughput par rapport aux modèles standards.
Les Relaxed Recursive Transformers surpassent donc les modèles vanilla, permettant de réduire drastiquement le temps de calcul par token tout en conservant une qualité de génération élevée, idéale pour les applications IA en temps réel.
⚙️ De la théorie à la pratique : vers une IA plus accessible et performante
Avec les Relaxed Recursive Transformers, Google propose un modèle qui conjugue compacité et puissance, permettant une IA accessible à plus d’organisations et adaptée aux contraintes de déploiement en production. Cette avancée place le partage de paramètres et les adaptations de faible rang au cœur de l’optimisation des LLMs, un changement qui pourrait profondément transformer l’écosystème des modèles de langage.
#IntelligenceArtificielle #LLMs #MachineLearning #OpenSource #RelaxedRecursiveTransformers #GoogleAI #LayerTying #EfficacitéAI #LoRA #ThroughputOptimisation #EarlyExiting
🚀 Google redéfinit les grands modèles de langage : les Relaxed Recursive Transformers… was originally published in P2Enjoy SAS (IA & Web3) on Medium, where people are continuing the conversation by highlighting and responding to this story.