🎉 SVDQuant : La Révolution de la Quantification 4-Bit pour les Modèles de Diffusion en IA 🎉
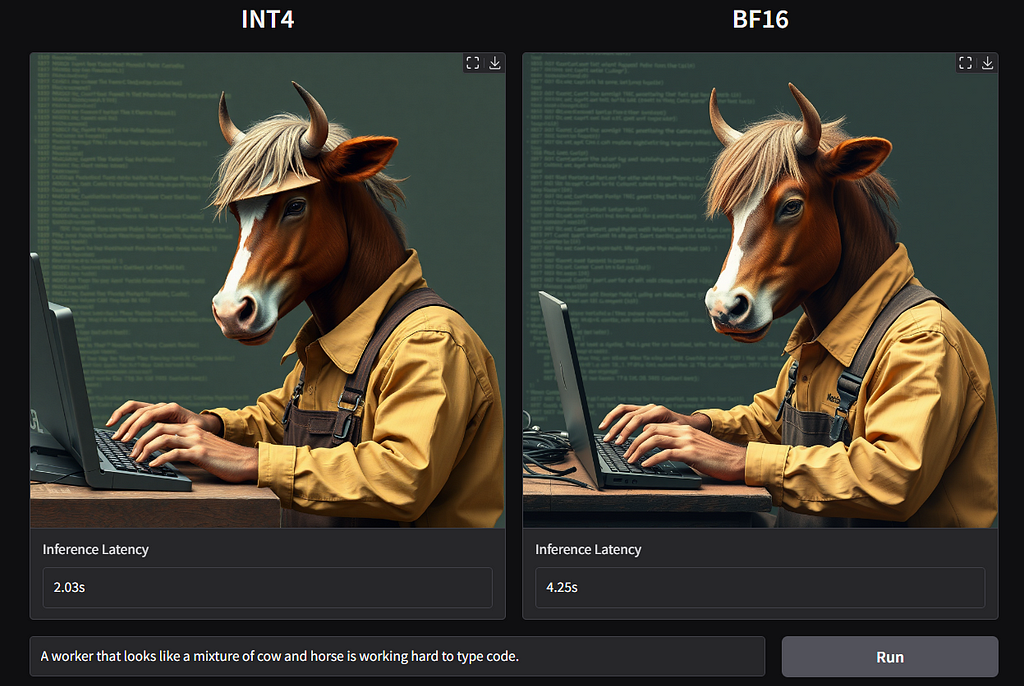
🧠 Les modèles de diffusion atteignent des niveaux inégalés en génération d’images, mais le prix de cette qualité est élevé : mémoire colossale et latence accrue rendent leur déploiement difficile, surtout pour les applications en temps réel. Avec SVDQuant, une approche innovante de quantification post-entraînement, ces limitations s’effacent. Imaginez FLUX.1, un modèle de 12 milliards de paramètres, déployé sur un simple GPU 4090 de 16 Go avec une réduction de mémoire de 3,6× et un gain de vitesse de 8,7× par rapport au modèle 16-bit BF16 ! 💥

⚙️ Approfondissement Technique : Une Quantification 4-Bit avec Absorption des Valeurs Extrêmes
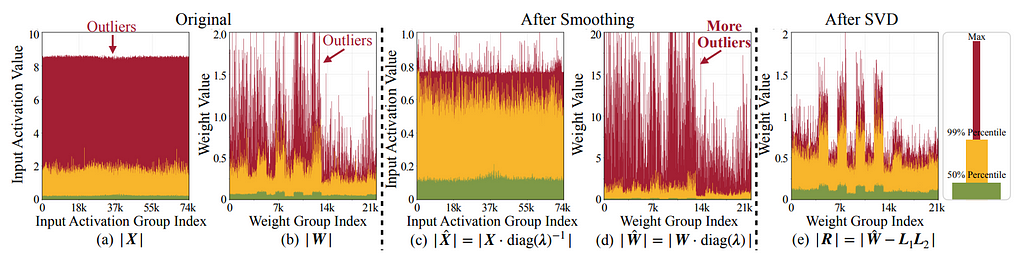
Les modèles traditionnels se heurtent à une barrière lors de la quantification des poids et des activations en 4 bits, car les valeurs extrêmes (“outliers”) perturbent la précision, ce qui pourrait remettre en question la fidélité dans des applications nécessitant une génération fine.
SVDQuant résout ce problème en absorbant ces valeurs extrêmes grâce à une branche basse-rang (low-rank) dédiée qui capture ces anomalies. Contrairement à des méthodes comme le smoothing, qui ne fait que redistribuer les outliers, SVDQuant utilise la Décomposition en Valeurs Singulières (SVD) pour identifier et séparer les composantes dominantes, isolant les éléments cruciaux dans une branche de précision 16 bits.
Le reste est ainsi traité en 4 bits sans perte significative de qualité, comme observé sur des modèles tels que PixArt-Σ et SDXL-Turbo, où SVDQuant maintient la précision des alignements texte-image et la richesse des détails visuels 📸✨.
🎛️ Nunchaku : Fusion Optimisée des Noyaux pour Réduire la Latence
Un défi subsiste cependant : l’implémentation naïve de la branche basse-rang introduirait une surcharge importante en raison de mouvements de mémoire répétés pour gérer les activations 16 bits. L’inférence engine Nunchaku co-conçu avec SVDQuant permet d’optimiser cette structure. La fusion des noyaux synchronise les calculs de la branche 16-bit basse-rang avec ceux de la branche 4-bit, limitant les transferts inutiles et réduisant le nombre d’appels de noyaux de moitié. Résultat : la surcharge devient quasi négligeable avec seulement 5 à 10 % de latence additionnelle, permettant à la branche basse-rang de fonctionner sans impact notable. ⚡
🎨 Qualité Visuelle Inégalée, Même en 4-Bit
La quantification 4-bit présente des défis pour la fidélité visuelle, mais SVDQuant parvient à préserver la qualité de génération. Comparé aux autres techniques 4-bit comme NF4 et W4A8, SVDQuant maintient une qualité d’image nettement supérieure, garantissant un alignement texte-image d’une précision exceptionnelle. Cette approche surpasse les méthodes existantes comme ViDiT-Q, où des styles tels que “dinosaur style” génèrent de véritables dinosaures par erreur, tandis que SVDQuant respecte fidèlement l’instruction stylistique.
🧩 Compatibilité avec LoRA sans Requantification
L’intégration de LoRA (Low-Rank Adapters) permet un fine-tuning efficace, mais nécessite souvent une requantification coûteuse. SVDQuant, quant à lui, élimine ces surcharges grâce à Nunchaku, qui optimise les accès en mémoire pour permettre l’intégration directe des LoRAs. En utilisant des styles comme “Ghibsky Illustration”, “Anime” ou “Yarn Art”, SVDQuant conserve une haute fidélité visuelle, permettant des adaptations stylistiques sans impact sur la performance. 🎭🎨

📈 Des Modèles de 12B Paramètres Accessibles pour Tous
SVDQuant et Nunchaku ouvrent la voie pour des applications interactives puissantes sur des dispositifs accessibles, favorisant ainsi des cas d’usage immersifs et productifs. L’exécution sur un seul GPU de 16 Go en mode 4-bit rend les modèles massifs de diffusion non seulement exécutables, mais aussi rapides et économes en mémoire, facilitant leur utilisation pour des entreprises cherchant à offrir des expériences IA de pointe. 🌐
🔗 Pour explorer les détails de ce projet open source développé par le MIT-Han-Lab :
https://github.com/mit-han-lab/nunchaku
🎥Démo SVDQuant en Action !
🔍 Tester vous-même : Mettez SVDQuant à l’épreuve et voyez comment il réduit la latence tout en conservant la fidélité visuelle :
https://hanlab.mit.edu/projects/svdquant
Sources
- Document PDF : SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models
https://arxiv.org/pdf/2411.05007v2.pdf - Dépôt GitHub Nunchaku : Open source quantization library and inference engine
https://github.com/mit-han-lab/nunchaku
#AI #Quantization #OpenSource #DeepLearning #DiffusionModels #4bitAI #SVDQuant #InnovationTech #LoRA #MachineLearning
🎉 SVDQuant : La Révolution de la Quantification 4-Bit pour les Modèles de Diffusion en IA 🎉 was originally published in ia-web3 on Medium, where people are continuing the conversation by highlighting and responding to this story.